Automated Warranting Detection Codebook
The Automated Warranting Detection Codebook captures both the process of detecting key discourse patterns in biomedical publishing data and orienting rhetoricians to machine learning applications for their own work. In this project, I have developed and refined my skills with statistical computing language R to undertake a large-scale textual analysis project on a corpus of FDA drug funding profiles and disclosures in order to determine if and how different research funding profiles and their attendant conflicts of interest change patterns of discourse in biomedical publishing.
Click on each image for more information on some of the feature analysis methods we use.
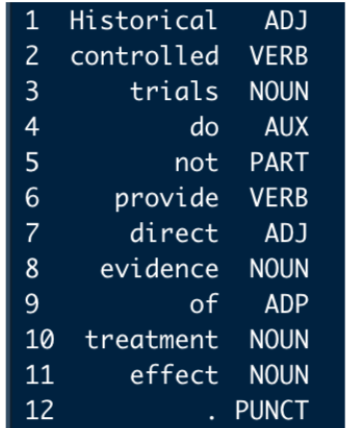


I use R to conduct language feature identification on a corpus of drug funding profiles and disclosures for warranting language, a mode of argumentation designed to lend support to bodies of evidence not entirely trusted by the audience. This analysis contributes to ongoing inquiry focused on the effects of conflicts of interest on both medical discourse and outcomes, particularly as those conflicts relate to the relationship between funders, products, and the Food and Drug Administration. In addition to identifying and testing feature identification methods, I contextualized machine learning for a rhetoric and technical communication audience in literature reviews and sections of our co-written article.